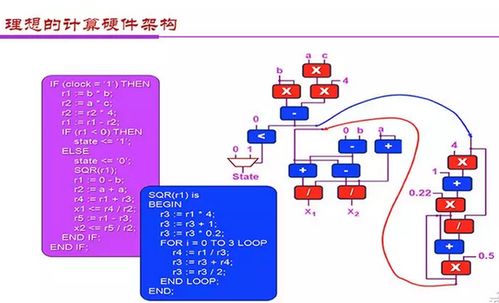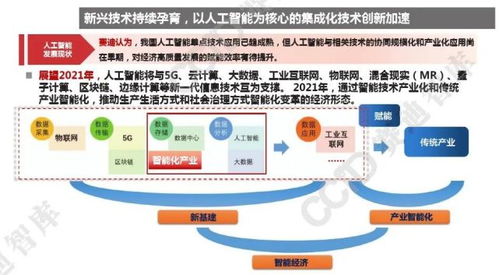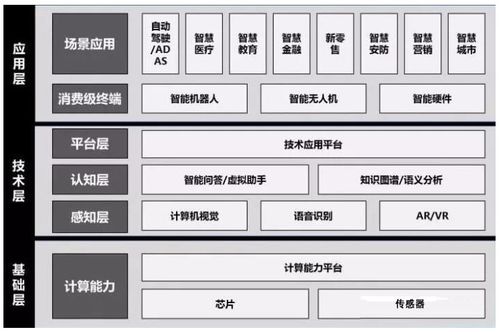
人工智能的飞速发展,特别是以深度学习为代表的神经网络技术的广泛应用,离不开其背后坚实的“基础设施”与“基础软件”。这两者共同构成了人工智能技术落地与创新的核心底座,如同计算机时代的操作系统与芯片,是智能时代不可或缺的基石。
一、人工智能神经网络基础设施的核心构成
人工智能神经网络基础设施是一个多层次、系统化的技术栈,其核心旨在为神经网络模型的训练、部署、推理和管理提供高效、稳定、可扩展的支撑环境。其主要构成包括:
- 计算硬件层:这是算力的物理承载。核心是GPU(图形处理器)、TPU(张量处理器)、NPU(神经网络处理器) 等专为并行矩阵运算优化的加速芯片。它们提供了训练庞大神经网络模型所需的海量浮点计算能力。高速互联网络(如NVLink、InfiniBand)和大容量存储系统(如高速SSD、分布式文件系统)也是关键,它们决定了数据在计算单元间流动的效率。
- 集群与调度层:单个计算设备的能力有限,现代AI基础设施通常由成百上千的加速卡组成计算集群。资源管理与调度系统(如Kubernetes及其针对AI的扩展KubeFlow,或各云厂商的专有调度器)是这一层的“大脑”,负责将计算任务(训练Job或推理服务)高效、公平地分配到集群中的硬件资源上,实现资源利用率最大化。
- 存储与数据层:高质量、大规模的数据是神经网络的“燃料”。此层包括数据湖/仓库(用于存储原始和加工后的数据)、特征平台(用于管理、共享和复用模型特征)、以及数据流水线工具(如Apache Spark、Airflow),确保数据能够被高效地预处理、清洗并输送给训练流程。
- 训练与推理平台层:这是直接面向AI开发者的工作台。它提供了从模型开发、分布式训练、超参数调优、模型评估到模型部署上线的一站式平台能力。平台需要自动处理分布式训练的通信优化、容错恢复、实验跟踪等复杂工程问题,让研究者能更专注于算法创新。
二、人工智能基础软件开发的关键领域
基础软件是连接上层AI应用与底层硬件基础设施的桥梁,它将硬件能力抽象化、标准化,提供给开发者易用的编程接口和工具链。其关键领域包括:
- 深度学习框架:这是AI开发的“操作系统”,是基础软件的核心。主流的框架如 TensorFlow、PyTorch、JAX 等,提供了定义神经网络结构、自动微分、梯度计算和优化算法的基础API。它们的设计直接影响了算法研究的灵活性与工程部署的效率。当前趋势是追求 “动态图”的易用性 与 “静态图”的部署性能 的统一。
- 编译器与运行时:为了在不同硬件上获得极致性能,需要专门的编译器将高级框架定义的模型,优化并编译成能在特定硬件(如GPU、TPU、手机芯片)上高效执行的代码。例如 XLA(加速线性代数)、TVM、MLIR 等。运行时系统则管理编译后模型在设备上的执行、内存分配和算子调度。
- 模型仓库与格式标准:为了解决模型复用和跨平台部署的问题,需要统一的模型格式和存储仓库。ONNX(开放神经网络交换) 格式旨在让模型能在不同框架间迁移和部署。模型仓库(如Hugging Face Model Hub)则促进了模型的共享、版本管理和协作。
- 系统优化库:提供高度优化的基础算子实现,如 cuDNN(针对NVIDIA GPU的深度学习原语库)、oneDNN(针对Intel CPU的优化库)等。这些库是框架底层性能的保障。
- 监控、可解释性与安全工具:随着AI系统走向生产环境,监控模型性能衰减(如数据漂移)、提供模型决策的可解释性、以及保障模型安全(防止对抗攻击)的软件工具变得日益重要,它们构成了AI基础软件的“运维与安全”层面。
三、核心协同:基础设施与基础软件的融合
基础设施与基础软件并非孤立存在,而是深度协同、共同演进:
- 软件定义硬件:基础软件(如编译器和框架)的发展,驱动着硬件设计的方向(如对稀疏计算、低精度运算的支持)。
- 硬件赋能软件:新型硬件(如TPU)的出现,要求并催生新的软件栈和编程模型(如围绕TPU设计的JAX框架生态)。
- 一体化栈优化:领先的科技公司(如谷歌、微软、Meta)正在致力于打造从芯片、硬件系统到框架、平台的全栈垂直优化,以释放最大的端到端性能。例如,谷歌的 TPU + JAX + TensorFlow 生态,以及英伟达的 GPU + CUDA + TensorRT 全栈方案。
人工智能神经网络基础设施与基础软件开发,是支撑当前人工智能从实验室走向千行百业、从理论创新迈向大规模产业应用的两大支柱。其核心目标是 降低AI研发与部署的技术门槛和成本,提升计算资源的利用效率,并保障AI系统在生产环境中的可靠性、可扩展性和可维护性。随着大模型、自动驾驶、科学智能等领域的深入发展,对更强大、更高效、更易用且更绿色的AI基础设施和基础软件的需求将愈发迫切,这将继续是学术界和产业界投入与创新的焦点所在。